Matrix Dataset: A Revolutionary Bilingual AI Pre-training Corpus
2077AI Foundation proudly announces our open-source project — the Matrix Dataset. As pioneers in AI data standardization and advancement, we are committed to unlocking AI's potential through high-quality data, accelerating AI development, and nurturing an efficient, thriving AI data ecosystem. The Matrix Dataset is a crucial component of this vision.
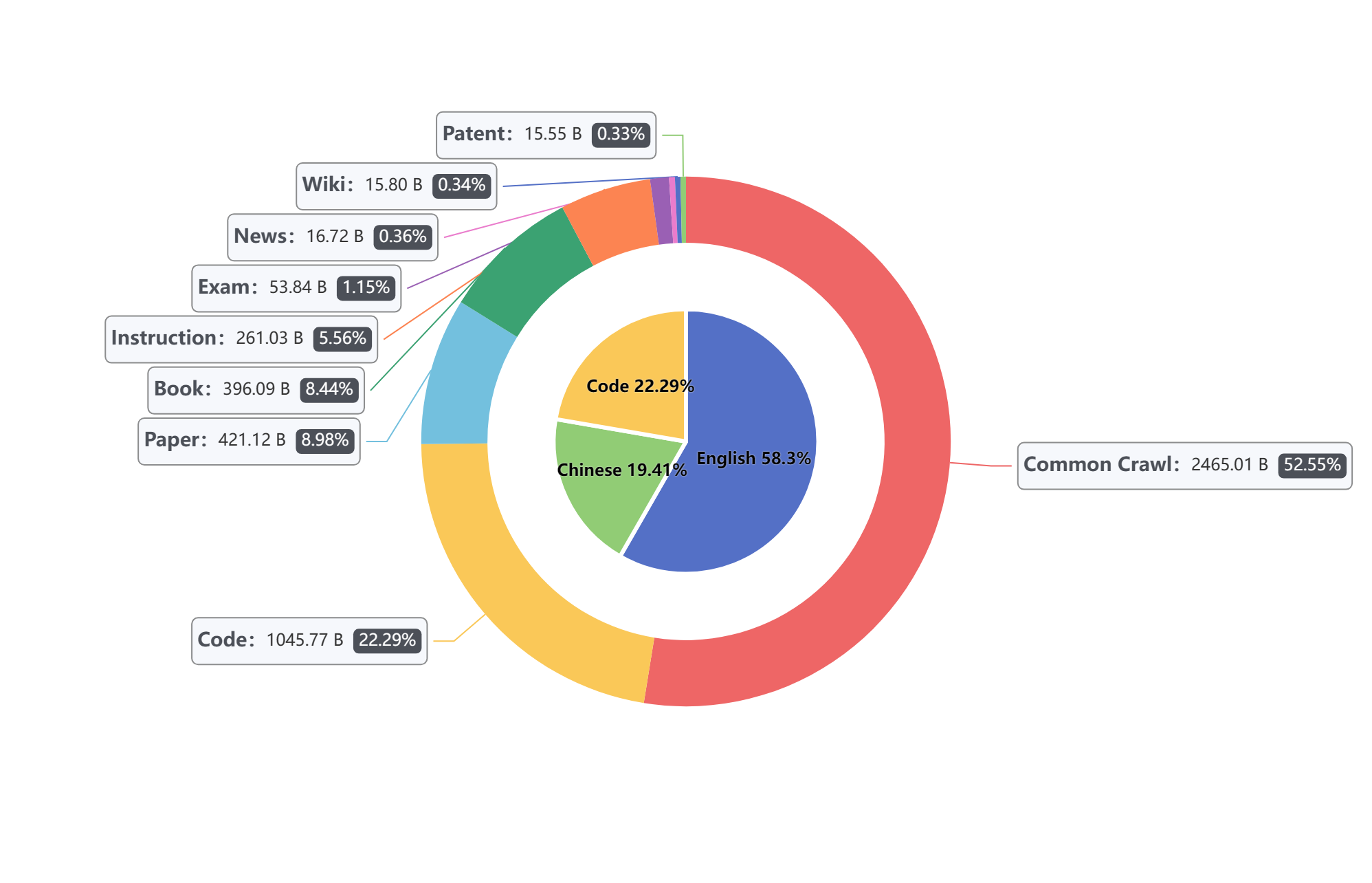
Statistics of the Matrix Pile Data Distribution: The inner pie chart represents the languagedistribution, while the outer loop indicates the proportion of meta-categories in the corpus.
What is the Matrix Dataset?
Matrix is a high-quality bilingual (Chinese-English) dataset containing 4690 billion tokens. It stands as the only large-scale bilingual pre-training dataset in the open-source community that can be used directly without additional calibration or validation. Its uniqueness lies not only in its scale but also in its meticulously designed data processing pipeline and diverse data sources, ensuring both high quality and broad applicability.
Diversity of Data Sources
We built this corpus from the ground up, encompassing a wide range of topics, primarily including:
- Integration of existing open-source pre-training data
- Additional Chinese, mathematics, and science exam data, as well as Wikipedia data collected from Common Crawl (CC)
- PDF documents converted to text via OCR technology and incorporated into the dataset
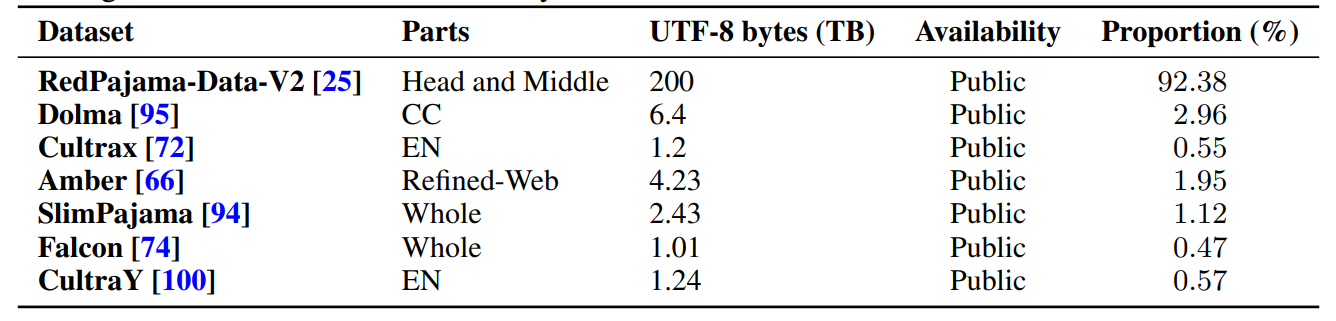
The composition sources of re-processed English web subset. The proportion denotes dividing the size of the current dataset by the total size of the whole dataset.
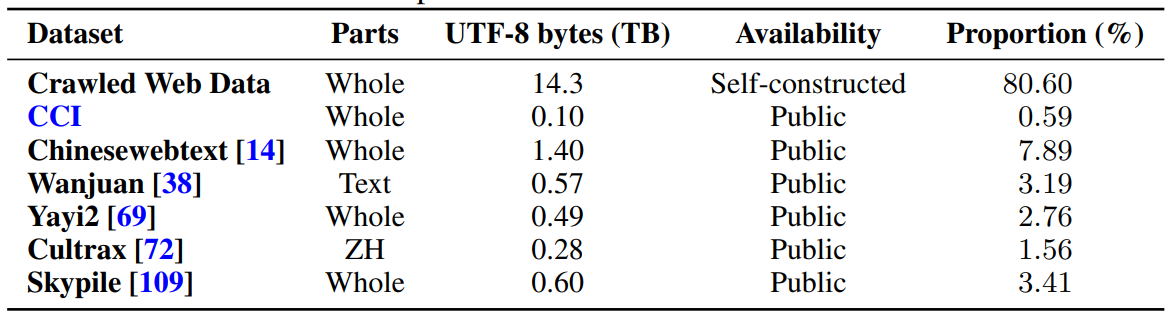
The composition sources of the Chinese web subset.
Meticulous Data Processing
The excellence of the Matrix Dataset stems from our carefully designed data processing pipeline:
- High-standard cleaning and filtering thresholds
- Strict deduplication strategies, including substring-level deduplication
- Post-calibration processing for OCR data
Through this rigorous processing workflow, we retained only a small portion of the original data: 4% of existing corpora and 19% of crawled corpora. Each data cleaning rule was repeatedly sampled and confirmed by team members, ensuring extremely high-quality standards for both Chinese and English data.
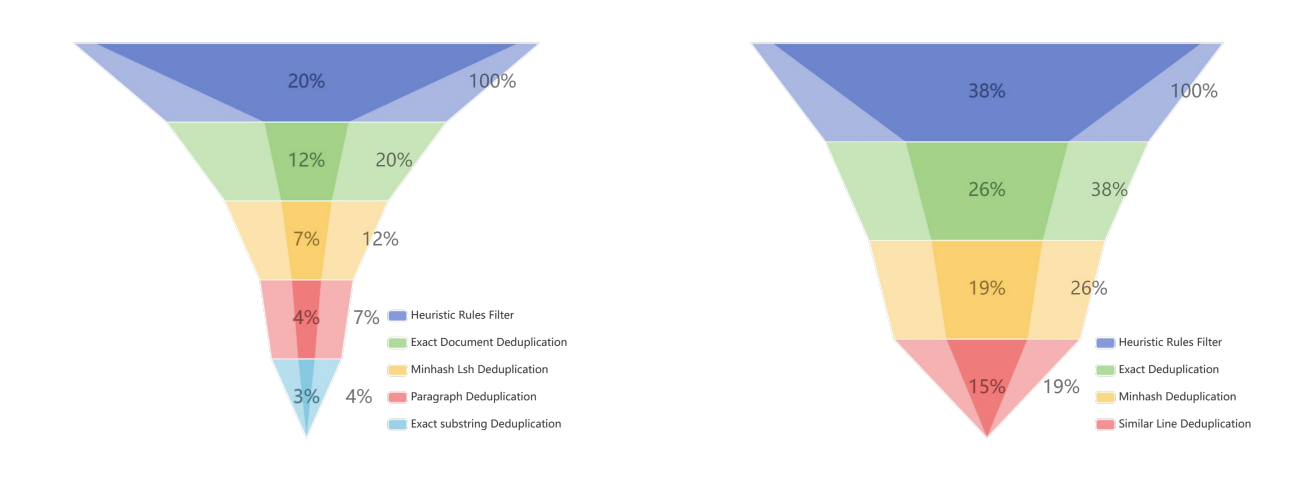
left: Re-processing retention rates; right: Processing retention rates, Funnel Diagram for the two main data pipelines. The darker part of each row represents the retention proportion for each processing step and the lighter one for the filtered corpora.
Optimized Data Composition
To maximize pre-training effectiveness, we adopted a heuristic data composition strategy:
- Pre-training is divided into two stages, with CC data included in the first stage and removed in the second
- Manual increase in the proportion of code, books, and document-type data
- Integration of deepseek-math and OCR pipelines, significantly enhancing training performance

Details of Heuristic Rules for English Texts
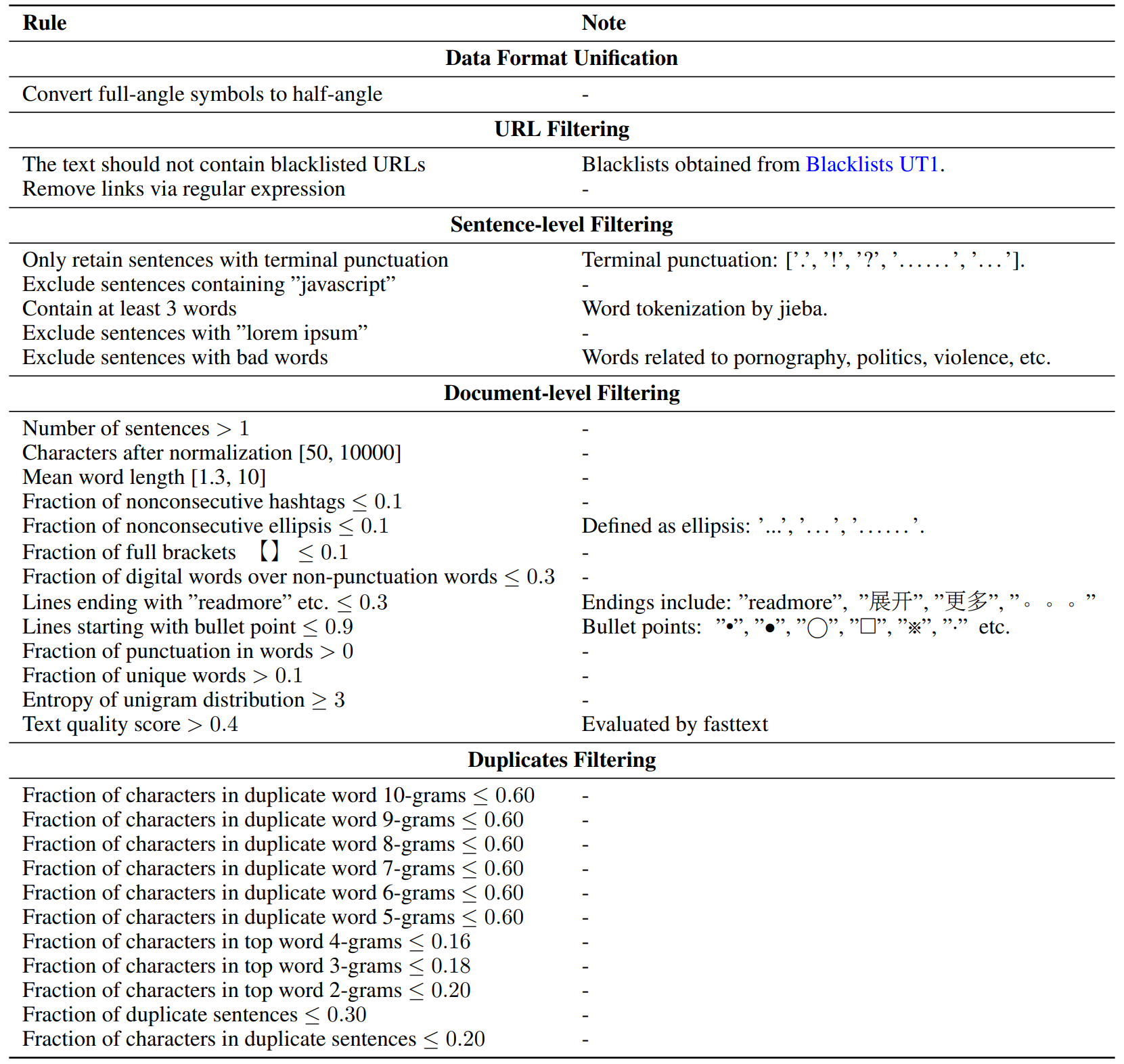
Details of Heuristic Rules for Chinese Texts.
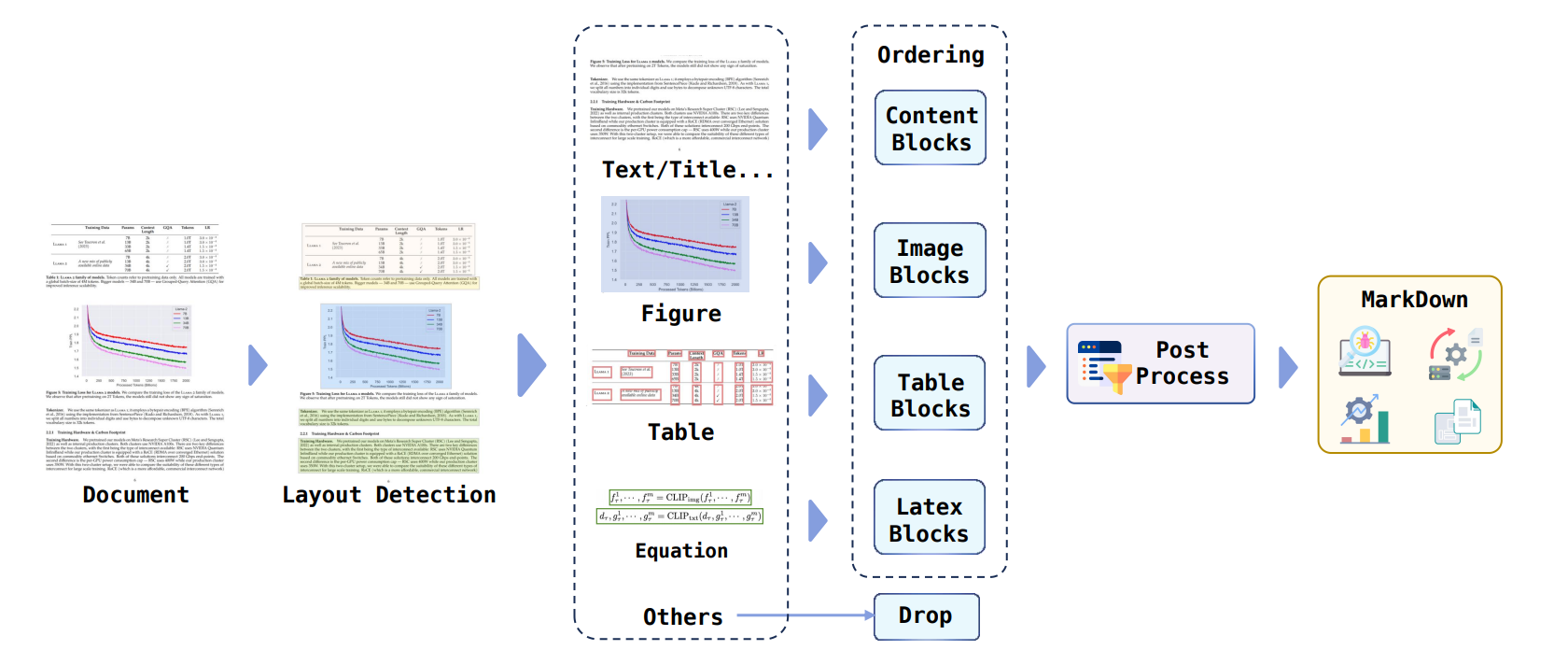
The document conversion framework is composed of various sub-models for different parts.
Commitment to Open Source
Adhering to the principles of openness and sharing, we have not only open-sourced all the data but also made public the code for all processing pipelines, including filtering, deduplication, document conversion, and all other procedures. This allows researchers and developers to delve into every step of data processing and even adjust and optimize according to their needs.
Join Us in Shaping the Future of AI
The launch of the Matrix Dataset marks a new milestone in AI pre-training data. We cordially invite AI researchers and developers worldwide to join us in leveraging this rich resource, pushing the boundaries of AI technology, and collectively shaping the future of AI.